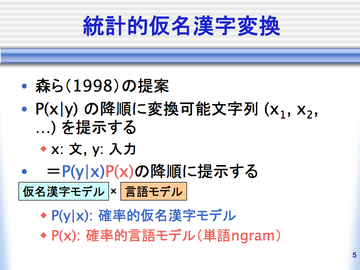
統計的仮名漢字変換では、与えられた仮名文字列の入力yに対して変換候補 xを条件付き確率P(x|y)の降順に提示します。仮名文字列が来たときに仮名漢字 交じり文になる確率です。この確率値が高い順に変換結果が並んでいて くれればいいわけです。言い換えると、確率値最大のものがもっとも尤もらしい 変換候補となり、尤もらしさ順に確率値が並んでいることが統計的仮名漢字変換 の基本原理となります。
さて、直接P(x|y)を推定する方法があればそのまま仮名漢字変換に用いること ができるのですが、一般にこの確率値を直接推定することは難しいため、 近似を用いて推定することになります。
この定式化は統計的機械翻訳や音声認識と同様で、ベイズの定理を用いることに よってP(x|y)はP(y|x)とP(x)の積として推定することができます。この定式化において、 仮名漢字交じり文xの生起確率P(x)は確率的言語モデルと呼ばれ、 P(y|x)は確率的仮名漢字変換モデルと呼ばれます。以下でそれぞれについて説明します。
確率的言語モデルとは、与えられた文字列が与えられた言語の文である尤度を 数値化したものです。こういった言語モデルは統計的機械翻訳や音声認識でも 用いられています。最も一般的に用いられている確率的言語モデルは単語 n-gram モデルで、このモデルは文を単語列からなるものと見なして文頭から順に単語を 予測します。

日本語入力の場合、単語境界が示されないため、仮名漢字変換においては 単語分割が最初に大きな問題となります。この問題を解決するために、単語 n-gram モデルに基づく自動単語分割器が提案されています(末尾の論文リスト参照)。 こういった自動単語分割器を用い、文字列xとして与えられる文の確率が最大と なるような単語分割が、いちばんもっともらしい単語分割だと考えられます。
確率的仮名漢字変換モデルとは、仮名漢字交じり文xが与えられたときの キーボードからの入力記号列yの確率を表します。単語列wが与えられたときの 確率的仮名漢字変換モデルによる確率P(y|w)は、単語分割と読みが付与された コーパスから最尤推定によって計算します。

単語候補を列挙するシステムは、入力記号列yを受け取りあらゆる部分文字列 から変換可能な単語列wを出力します。動的計画法(Viterbi 探索)を用いれば 効率的に1-best解を求めることができます。N-best の候補を出力するには後ろ向き A*探索を使用します。
ChaIME では単語に品詞情報を付与する必要がないので単語登録は簡単ですが、 専門用語や新語などへの対応が課題となっています。Social IME ではユーザ間で 辞書を共有することによってこの問題に対処しており、うまく協力してユーザの 手間を最大限に減らして辞書のメンテナンスを行えるようにしたいです。
また、サーバ側に蓄積された変換ログを用いて、スペルミスの自動訂正機能を 備えた入力メソッドや、予測入力機能を導入するつもりです。
| 名前 | 手法 | コーパス | 利点 | 欠点 |
|---|---|---|---|---|
| Anthy | 最大エントロピー法 | 独自コーパス(1万文) | 機械学習による高精度な変換。文節の概念がある。Windows, Mac, Linux などさまざまなプラットホームで動作する。ユーザが多く、Linux ディストリビューションではデファクトスタンダードになりつつある。 | 複雑なモデルとヒューリスティックなパラメータ推定。付属語辞書などのカバー率による再現率の低下。 |
| Sumibi | マルコフモデル {1, 2, skip2}-gram | Web データ (Wikipedia、はてな等) 数 GB? | ユーザが単語分かち書きするので単語分割ミスがない。 任意のデータを学習に使うことができる。ブラウザから使える。 | 単語分割を明示的に指定する必要がある。単語単位でしか変換できず、 辞書にない単語は変換できない。 |
| Mana (shinji) | 隠れマルコフモデル | IPADic による(京大コーパス4万文) | 確率的言語モデルによる高精度な変換。単語単位での変換をサポート。 ChaSen のコードを参考にしている。 | コーパスのサイズが小さい。仮名漢字変換モデルが考慮されていない。 |
| Ajax IME (mecab-skkserv) | 条件付き確率場(CRF) | IPADic による(京大コーパス4万文) | 識別モデルによる高精度なパラメータ推定。1文の変換結果の N-best 解から文全体 の変換結果を選択。ブラウザから使える。 | コーパスのサイズが小さい。単語(文節)単位での変換をサポートしていない。 仮名漢字変換モデルが考慮されていない。 |
| ChaIME | マルコフモデル {1,2}-gram | Google 日本語 N グラム(200億文から抽出した N グラムで、200万 unigram, 8,000万 bigram のタイプ) | Google 日本語 N グラムに出てくる単語なら自動で変換できる。 コーパスが巨大なのでデータの過疎性の問題の影響を受けにくい。 単語分割も Google 日本語 N グラムを用いて自動単語分割する。 | 表記をそのまま用いているのでモデルファイルが巨大(数GB)になる。 単語分割を独立したステップとして扱っていないため、 文字単位で探索する必要があり、探索時間がかかる。 |